

Intertextuality of the Chinese Classics and the Zhou Bronze Inscriptions




Intertextuality of the Chinese Classics and the Zhou Bronze Inscriptions
Having achieved proof of concept in adapting the TextPair intertextual framework to Chinese texts with the 24 Histories
二十四史, we are now working to align all extant pre-Song Chinese excavated and transmitted texts. We recently aligned 63 premodern Chinese classics (see image above, network analysis using eigenvector centrality reveals the importance of the Histories within that corpus) and secondly, systematized and aligned all inscriptions longer than 10 graphs in the Zhou inscriptional corpora. As a final step, we combined these to find where the 63 classics employ any phrases of at least 4 characters from the Zhou inscriptions (most of these are quotations in and from the Poetry 詩). Our next step is to bring in other corpora of pre-Tang excavated manuscripts (Warring States, Dunhuang and others) while expanding the post-Han corpus of received texts and align all of them together in a public online search interface and interactive network.
The Digital Etymological Dictionary of Old Chinese 《古漢語詞源字典(網絡版)》 1.0
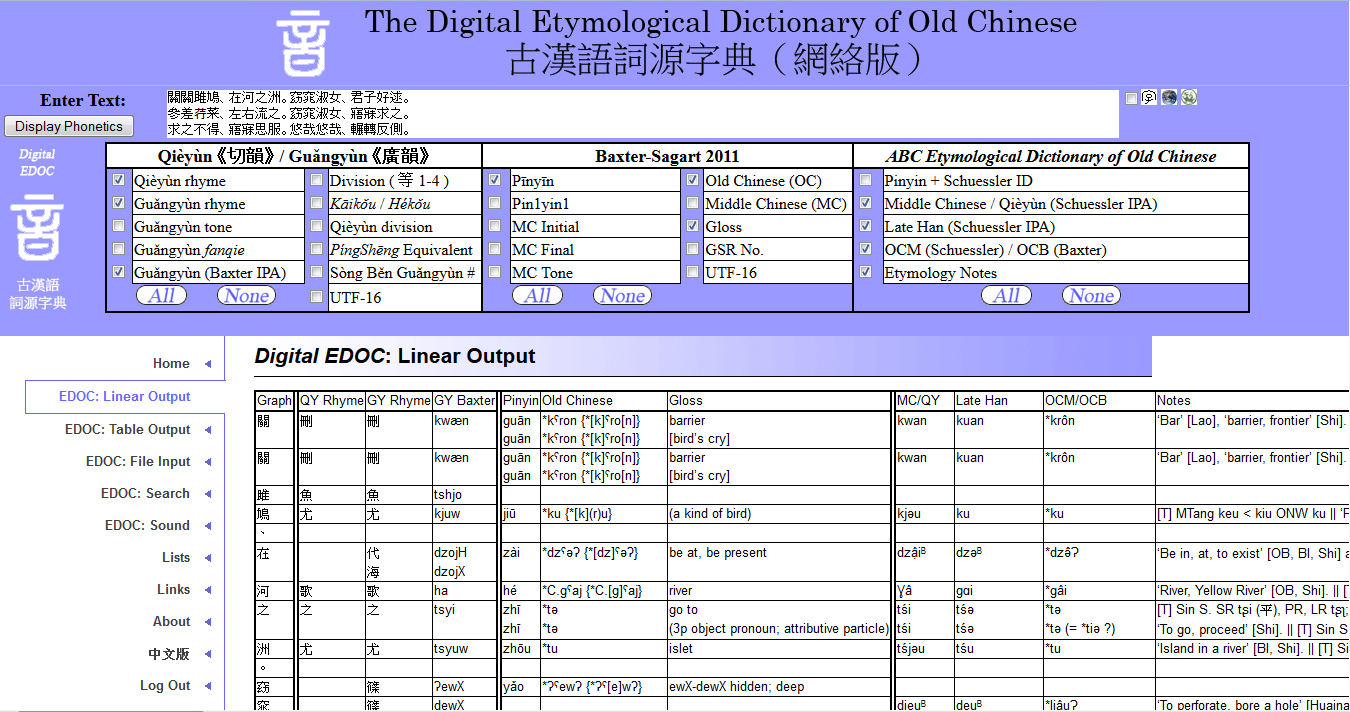
The Digital Etymological Dictionary of Old Chinese 《古漢語詞源字典(網絡版)》 1.0
The Digital Etymological Dictionary of Old Chinese is a new type of digital interface for Chinese texts. Using this interface, one can efficiently approximate the sounds of Chinese throughout history and perform comparative analyses of phonetic structures and phonorhetorical devices within the texts, from ancient times through the modern era.
chapakhana 2.0 (now featuring ArcGIS Data-Driven Web Apps)

chapakhana 2.0
chapakhana is a website designed to illustrate the rise of the printing press across South Asia in a series of interactive maps, from the establishment of the first movable type press in 1556 until the year 1900. Demonstrating the impact of global technology transfer, chapakhana offers users the opportunity to visualize the extent of printing activity in the Indian subcontinent up until the end of the nineteenth century and to identify when printing first came to a particular location. The names of early printing presses, their proprietors, printers, and editors are provided to make visible the many known and unknown pioneers of print in the Indian subcontinent. Taken together, the maps and additional materials on the website provide an extraordinary window into the vibrant history of printing in South Asia.
Digitization and Systemization of the 1594-1860 German book fair Catalogues: the Messkataloge
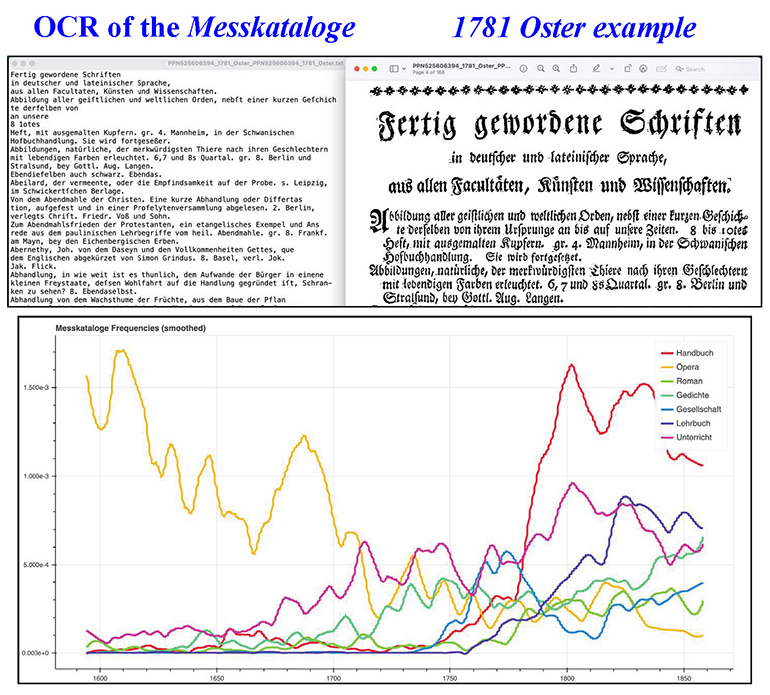
Digitizing the Messkataloge
In 2022 we undertook a project to harness the world’s most advanced Optical Character Recognition (OCR) systems and convert all 65,658 pages of the 1594-1860 Messkataloge to machine-readable plaintext, achieving over 98% accuracy and resulting in the first digital database for German book history. This work has opened up exciting new possibilities, as scholars can now search the data for insights into, for example: where books were published during the formative periods of German publishing, the rise and fall of particular genres, religious writings, or the declining dominance of Latin, with a precision hitherto unmatched (particularly for the 19th century).
To aid scholars, librarians, and book historians we also developed an open-source custom version of Google’s N-Gram Viewer via which one can plot relative and absolute word frequencies over time, determine covariance between terms, and investigate the wealth of data in the Messkataloge for any time period during its production.
The TextPAIR Viewer (TPV) 1.0
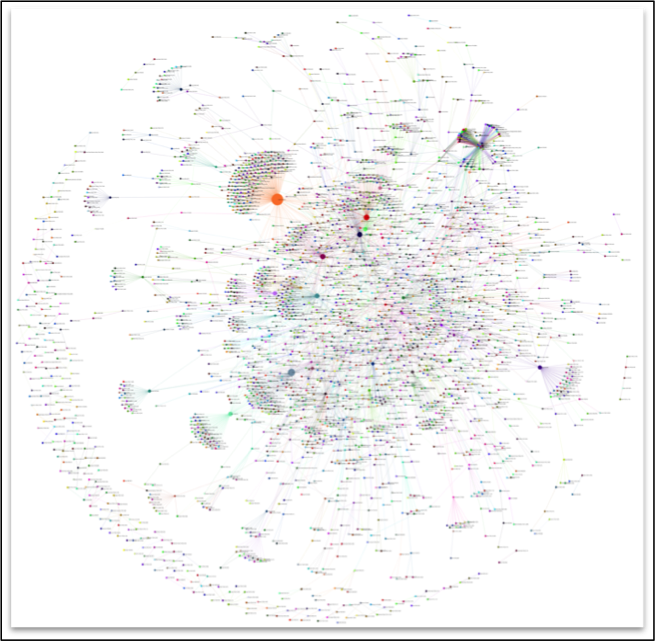
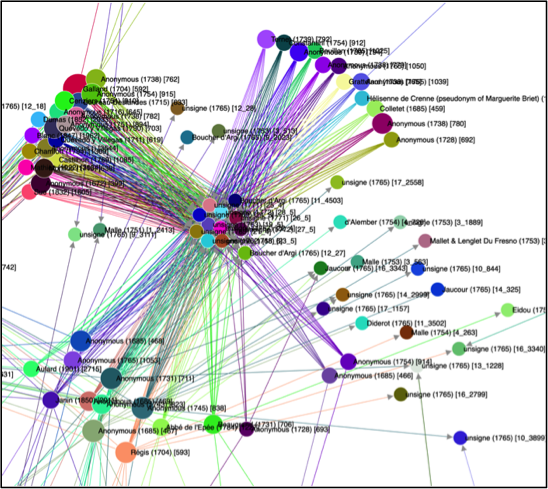


The TextPAIR Viewer (TPV) 1.0
The TextPAIR Viewer (TPV) is a new visualization toolkit for the analysis of large-scale intertextual text alignments (aka "text reuse" or "parallel passages"). The TPV facilitates the exploration of tens of thousands (up to millions) of text alignments in any textual corpus. The above screenshots exemplify its use for the analysis of over 7,000 parallel passages between Diderot's Encyclopédie and 3,500 contemporaneous works of French literature, and for the 322,000 parallel passages TextyPAIR uncovered within and between the 24 Chinese Histories (24 historiographies spanning 90 BCE to 1927, over 40 million characters in total).
The 24 Chinese Histories 二十四史 in Philologic4


The 24 Chinese Histories
The "24 Chinese Histories 二十四史 in Philologic" is a multi-faceted text analysis search interface and intertextual text-alignment algorithm that enables deep exploration and unparalleled configurable lexical analyses of the corpus of 3,213 volumes (roughly 40 million words) that comprise the 24 official Chinese histories, from the Shi ji dating to 91 BCE to the Qing Shi Gao published in 1927. For a brief overview of the source corpus, see the entry on Wikipedia.
chapakhana 1.0
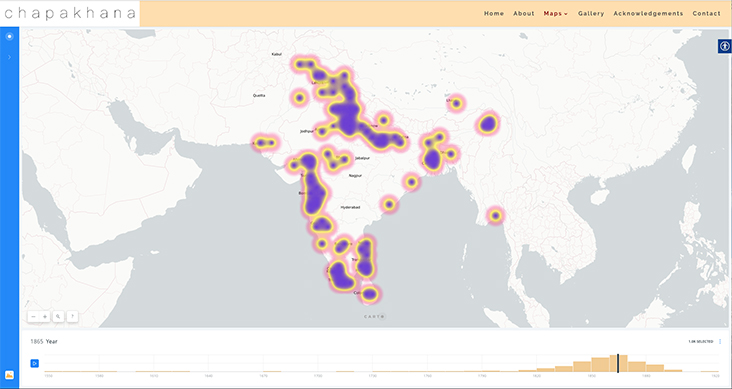
chapakhana
chapakhana is a website designed to illustrate the rise of the printing press across South Asia in a series of interactive maps, from the establishment of the first movable type press in 1556 until the year 1900. Demonstrating the impact of global technology transfer, chapakhana offers users the opportunity to visualize the extent of printing activity in the Indian subcontinent up until the end of the nineteenth century and to identify when printing first came to a particular location. The names of early printing presses, their proprietors, printers, and editors are provided to make visible the many known and unknown pioneers of print in the Indian subcontinent. Taken together, the maps and additional materials on the website provide an extraordinary window into the vibrant history of printing in South Asia.
The Sign And Gesture Archive (SAGA)

The Sign And Gesture Archive (SAGA)
The Sign And Gesture Archive (SAGA) is a video data library for gesture, sign and spoken language data. Its holdings represent over 40 years of data collection, including tens of thousands of video files, thousands of coding and annotation files, and rich metadata for each source. Basic and Advanced search mechanisms are built into the user interface to allow for detailed searches and comparative analyses to be undertaken by researchers in the fields of psychology, linguistics, sign and gesture.
The Visual Text Explorer
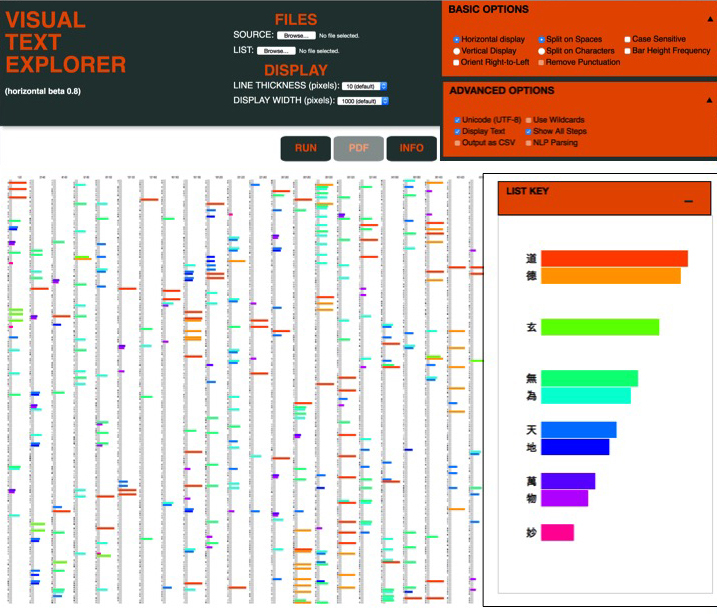
The Visual Text Explorer
The Visual Text Explorer is a user-customizable interactive digital visual interface designed for analytics of words and phrases in user-provided sources, allowing for simultaneous close reading and multidimensional data analytics.
Digital Resources for Sinologists (1.0)
Dissertation Reviews: "Digital Resources for Sinologists (1.0)"
Holger Schneider and I put together this two-part overview of the best digital resources available for Sinology and Chinese language learning. Part I provides a general rubric for the evaluation of digital dictionaries, with an eye toward the benefits of using multireferential databases and modern computational tools in lexicography. Part II is an annotated list of over fifty websites and software packages, representing what we feel are the very best digital resources available for sinologists and learners of Chinese. Subcategories include General Dictionaries/Lexical Tools, Learning and Translation Tools and Encyclopædia (large-scale text repositories). The article has since been converted into a Wiki, available online at http://sinology-resources.wikia.com/.
Intertext (beta 0.8)
IntertextThe Intertext "Intertextuality Analyzer", currently in the beta stage of development, is a tool which allows for the automated detection of patterns of vocabulary and terminology both within and across specific sets of digital texts as provided by the user. Via this tool one can trace specific uses of vocabulary across thousands of years of texts, providing concrete indications of influential tropes, their likely origins and how they changed over time. Patterns of textual citation and paraphrase, often unmarked in early Chinese texts, are also easily indicated and subtle differences in their transmission can be traced from text to text. Users will either be able to allow the application to detect commonalities between the texts, or indicate specific criteria (lists of words or phrases) to track across the texts. The output provides the full citation for each result detected, and will eventually include a full visual interface of the charts, graphs and networks which can be generated from the data results.